14. Inferential Statistics¶
The great tragedy of science - the slaying of a beautiful hypothesis by an ugly fact.
—Thomas Huxley
Truth in science can be defined as the working hypothesis best suited to open the way to the next better one.
—Konrad Lorenz
Recall that Matthias Mehl and his colleagues, in their study of sex differences in talkativeness, found that the women in their sample spoke a mean of 16,215 words per day and the men a mean of 15,669 words per day [MVRamirezE+07]. But despite observing this difference in their sample, they concluded that there was no evidence of a sex difference in talkativeness in the population. Recall also that Allen Kanner and his colleagues, in their study of the relationship between daily hassles and symptoms, found a correlation of 0.6 in their sample [KCSL81]. But they concluded that this finding implied a relationship between hassles and symptoms in the population. These examples raise questions about how researchers can draw conclusions about the population based on results from their sample.
To answer such questions, researchers use a set of techniques called inferential statistics, which is what this chapter is about. We focus, in particular, on null hypothesis testing, the most common approach to inferential statistics in psychological research. We begin with a conceptual overview of null hypothesis testing, including its purpose and basic logic. Then we look at several null hypothesis testing techniques that allow conclusions about differences between means and about correlations between quantitative variables. Finally, we consider a few other important ideas related to null hypothesis testing, including some that can be helpful in planning new studies and interpreting results. We also look at some long-standing criticisms of null hypothesis testing and some ways of dealing with these criticisms.
14.1. Understanding Null Hypothesis Testing¶
14.1.1. Learning Objectives¶
Explain the purpose of null hypothesis testing, including the role of sampling error.
Describe the basic logic of null hypothesis testing.
Describe the role of relationship strength and sample size in determining statistical significance and make reasonable judgments about statistical significance based on these two factors.
14.1.2. The Purpose of Null Hypothesis Testing¶
As we have seen, psychological research typically involves measuring one or more variables within a sample and computing descriptive statistics. In general, however, the researcher’s goal is not to draw conclusions about the participants in that sample, but rather to draw conclusions about the population from which those participants were selected. Thus, researchers must use sample statistics to draw conclusions about the corresponding values in the population. These corresponding values in the population are called parameters. Imagine, for example, that a researcher measures the number of depressive symptoms exhibited by each of 50 clinically depressed adults and computes the mean number of symptoms. The researcher probably wants to use this sample statistic (the mean number of symptoms for the sample) to draw conclusions about the corresponding population parameter (the mean number of symptoms for clinically depressed adults).
Unfortunately, sample statistics are not perfect estimates of their corresponding population parameters. This is because there is a certain amount of random variability in any statistic from sample to sample. The mean number of depressive symptoms might be 8.73 in one sample of clinically depressed adults, 6.45 in a second sample, and 9.44 in a third. This will happen even though these samples are randomly selected from the same population. Similarly, the correlation (e.g., Pearson’s r) between two variables might be 0.24 in one sample, -0.04 in a second sample, and 0.15 in a third. Again, this can and will happen even though these samples are selected randomly from the same population. This random variability in statistics calculated from sample to sample is called sampling error. Note that the term error here refers to the statistical notion of error, or random variability, and does not imply that anyone has made a mistake. No one “commits a sampling error”.
One implication of this is that when there is a statistical relationship in a sample, it is not always clear whether there is a statistical relationship in the population. A small difference between two group means in a sample might indicate that there is a small difference between the two group means in the population. But it could also be that there is no difference between the means in the population and that the difference in the sample is just a matter of sampling error. Similarly, a Pearson’s r value of -0.29 in a sample might mean that there is a negative relationship in the population. But it could also be that there is no relationship in the population and that the relationship in the sample is just a matter of sampling error.
In fact, any relationship observed in a sample can be interpreted in two ways:
There is a relationship in the population, and the relationship in the sample reflects this.
There is no relationship in the population, and the relationship in the sample reflects only sampling error.
The purpose of inferential statistics is simply to help researchers decide between these two interpretations.
14.1.3. The Logic of Null Hypothesis Testing¶
Null hypothesis testing (or NHST) is a formal approach to making decisions between these two interpretations. One interpretation is called the null hypothesis (often symbolized \(H_0\) and read as “H-naught”). This is the idea that there is no relationship in the population and that the relationship in the sample reflects only sampling error. Informally, the null hypothesis is that the sample relationship “occurred by chance”. The other interpretation is called the alternative hypothesis (often symbolized as \(H_1\)). This is the idea that there is a relationship in the population and that the relationship in the sample reflects this relationship in the population.
Again, every statistical relationship in a sample can be interpreted in either of these two ways: It might have occurred by chance, or it might reflect a relationship in the population. So researchers need a way to decide between them. Although there are many specific null hypothesis testing techniques, they are all based on the same general logic. The steps are as follows:
Assume for the moment that the null hypothesis is true. There is no relationship between the variables in the population.
Determine how likely the sample relationship would be if the null hypothesis were true.
If the sample relationship would be extremely unlikely, then reject the null hypothesis in favor of the alternative hypothesis. If it would not be extremely unlikely, then retain the null hypothesis.
Following this logic, we can begin to understand why Mehl and his colleagues concluded that there is no difference in talkativeness between women and men in the population. In essence, they asked the following question: “If there were no difference in the population, how likely is it that we would find a small difference of d = 0.06 in our sample?” Their answer to this question was that this sample relationship would be fairly likely if the null hypothesis were true. Therefore, they retained the null hypothesis—concluding that there is no evidence of a sex difference in the population. We can also see why Kanner and his colleagues concluded that there is a correlation between hassles and symptoms in the population. They asked, “If the null hypothesis were true, how likely is it that we would find a strong correlation of +.60 in our sample?” Their answer to this question was that this sample relationship would be fairly unlikely if the null hypothesis were true. Therefore, they rejected the null hypothesis in favor of the alternative hypothesis—concluding that there is a positive correlation between these variables in the population.
A crucial step in null hypothesis testing is finding the likelihood of the sample result if the null hypothesis were true. This probability is called the p value. A small value of p value means that the sample result would be unlikely if the null hypothesis were true and leads to the rejection of the null hypothesis. A large value of p means that the sample result would be likely if the null hypothesis were true and leads the null hypothesis to be accepted. But how low must the p value be before the sample result is considered unlikely enough to reject the null hypothesis? In null hypothesis testing, this criterion is called \(\alpha\) (alpha) and is often set to .05. If the chance of a result as extreme as the sample result (or more extreme) is less than a 5% if the null hypothesis were true, then the null hypothesis is rejected. When this happens, the result is said to be statistically significant. If the chance of of a result as extreme as the sample result is greater than 5% when the null hypothesis is true, then the null hypothesis is retained. This does not necessarily mean that the researcher accepts the null hypothesis as true. It means that there is not currently enough evidence to conclude that it is false. For this reason, researchers often use the expression “fail to reject the null hypothesis” rather than something such as “conclude the null hypothesis is true”.
14.1.4. The Misunderstood p Value¶
The p value is one of the most misunderstood quantities in psychological research [Coh94]. Even professional researchers misinterpret it, and it is not unusual for such misinterpretations to appear in statistics textbooks!
The most common misinterpretation is that the p value is the probability that the null hypothesis is true or that the that the p value is the probability that the sample result occurred by chance. For example, a misguided researcher might say that because the p value is .02, there is only a 2% chance that the result is due to chance and a 98% chance that it reflects a real relationship in the population. But this is incorrect. The p value is really the probability of a result at least as extreme as the sample result if the null hypothesis were true. So a p value of .02 means that if the null hypothesis were true, a sample result this extreme would occur only 2% of the time.
You can avoid this misunderstanding by remembering that the p value is not the probability that any particular hypothesis is true or false. Instead, it is the probability of obtaining the sample result if the null hypothesis were true.
14.1.5. Role of Sample Size and Relationship Strength¶
Recall that null hypothesis testing involves answering the question, “If the null hypothesis were true, what is the probability of a sample result as extreme as this one?” As we have just seen, this question is equivalent to, “What is the p value?” It can be helpful to see that the answer to this question depends on just two considerations: the strength of the relationship and the size of the sample. Specifically, the stronger the sample relationship and the larger the sample, the less likely the result would be if the null hypothesis were true. That is, the lower the p value. This should make sense. Imagine a study in which a sample of 500 women is compared with a sample of 500 men in terms of some psychological characteristic, and Cohen’s d is a strong 0.50. If there were really no sex difference in the population, then a result this strong based on such a large sample should seem highly unlikely. Now imagine a similar study in which a sample of three women is compared with a sample of three men, and Cohen’s d is a weak 0.10. If there were no sex difference in the population, then a relationship this weak based on such a small sample should seem likely. And this is precisely why the null hypothesis would be rejected in the first example and retained in the second.
Of course, sometimes the result can be weak and the sample large, or the result can be strong and the sample small. In these cases, the two considerations trade off against each other so that a weak result can be statistically significant if the sample is large enough and a strong relationship can be statistically significant even if the sample is small. Figure 14.1: shows a rough guideline of how relationship strength and sample size might combine to determine whether a sample result is statistically significant or not. The columns of the table represent the three levels of relationship strength: weak, medium, and strong. The rows represent four sample sizes that can be considered small, medium, large, and extra large in the context of psychological research. Thus, each cell in the table represents a combination of relationship strength and sample size. If a cell contains the word Yes, then this combination would be statistically significant for both Cohen’s d and Pearson’s r. If it contains the word No, then it would not be statistically significant for either. There is one cell where the decision for d and r would be different and another where it might be different depending on some additional considerations, which are discussed below, in the section entitled, “Some Basic Null Hypothesis Tests”.
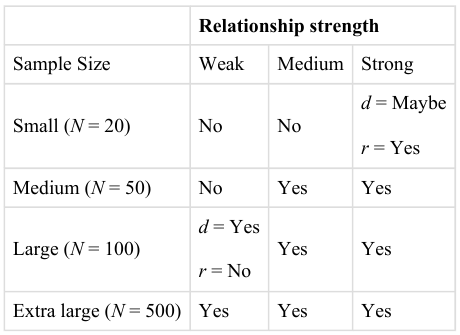
Fig. 14.1 How Relationship Strength and Sample Size Combine to Determine Whether a Result Is Statistically Significant¶
Although Figure 14.1: provides only a rough guideline, it shows very clearly that weak relationships based on medium or small samples are less likely to be statistically significant and that strong relationships based on medium or larger samples are more likely to be statistically significant. If you keep this lesson in mind, you will often know whether a result is statistically significant based on the descriptive statistics alone. It is extremely useful to be able to develop this kind of intuitive judgment. One reason is that it allows you to develop expectations about how your formal null hypothesis tests are going to come out, which in turn allows you to detect problems in your analyses. For example, if your sample relationship is strong and your sample is medium, then you would expect to reject the null hypothesis. If for some reason your formal null hypothesis test indicates otherwise, then you may need to double-check your computations and interpretations. A second reason is that the ability to make this kind of intuitive judgment is an indication that you understand the basic logic of this approach.
14.1.6. Statistical Significance Versus Practical Significance¶
Figure 14.1: illustrates another extremely important point. A statistically significant result is not necessarily a strong one. Even a very weak result can be statistically significant if it is based on a large enough sample. This is closely related to Janet Shibley Hyde’s argument about sex differences [Hyd07]. The differences between women and men in mathematical problem solving and leadership ability are statistically significant. But the word “significant” can cause people to interpret these differences as strong and important, perhaps even important enough to influence the college courses they take or even who they vote for. As we have seen, however, these statistically significant differences are actually quite weak, perhaps even “trivial”.
This is why it is important to distinguish between the statistical significance of a result and the practical significance of that result. Practical significance refers to the importance or usefulness of the result in some real-world context. Many sex differences are statistically significant (and may even be interesting for purely scientific reasons) but they are often not practically significant. In clinical practice, this same concept is often referred to as “clinical significance”. For example, a study on a new treatment for social phobia might show that it produces a positive effect that is statistically significant. Yet this effect still might not be strong enough to justify the time, effort, and other costs of putting it into practice. For example, easier and cheaper treatments that work almost as well might already exist. Although statistically significant, this result would be said to lack practical or clinical significance.
14.1.7. Key Takeaways¶
Null hypothesis testing is a formal approach to deciding whether a statistical relationship in a sample reflects a real relationship in the population or is just due to chance.
The logic of null hypothesis testing involves assuming that the null hypothesis is true, finding how likely the sample result would be if this assumption were correct, and then making a decision. If the sample result would be unlikely if the null hypothesis were true, then it is rejected in favor of the alternative hypothesis. If it would not be unlikely, then the null hypothesis is retained.
The probability of obtaining the sample result if the null hypothesis were true (the p value) is based on two considerations: relationship strength and sample size. Reasonable judgments about whether a sample relationship is statistically significant can often be made by quickly considering these two factors.
Statistical significance is not the same as relationship strength or importance. Even weak relationships can be statistically significant if the sample size is large enough. It is important to consider relationship strength and the practical significance of a result in addition to its statistical significance.
14.1.8. Exercises¶
Discussion: Imagine a study showing that people who eat more broccoli tend to be happier. Explain for someone who knows nothing about statistics why the researchers would conduct a null hypothesis test.
Practice: Use Figure 14.1: to try and determine whether each of the following results is statistically significant:
a. The correlation between two variables is r = -0.78 based on a sample size of 137.
b. The mean score on a psychological characteristic for women is 25 (SD = 5) and the mean score for men is 24 (SD = 5). There were 12 women and 10 men in this study.
c. In a memory experiment, the mean number of items recalled by the 40 participants in Condition A was 0.50 standard deviations greater than the mean number recalled by the 40 participants in Condition B.
d. In another memory experiment, the mean scores for participants in Condition A and Condition B came out exactly the same!
e. A student finds a correlation of r = 0.04 between the number of units the students in his research methods class are taking and the students’ level of stress.
14.2. Some Basic Null Hypothesis Tests¶
14.2.1. Learning Objectives¶
Conduct and interpret one-sample, dependent-samples, and independent-samples t tests.
Interpret the results of one-way, repeated measures, and factorial ANOVAs.
Conduct and interpret null hypothesis tests of Pearson’s r.
In this section, we look at several common null hypothesis testing procedures. The emphasis here is on providing enough information to allow you to conduct and interpret the most basic versions. In most cases, the online statistical analysis tools mentioned in Chapter 13 will handle the computations, as will programs such as Microsoft Excel and SPSS.
14.2.2. The t Test¶
As we have seen throughout this book, many studies in psychology focus on the difference between two means. The most common null hypothesis test for this type of statistical relationship is the t test. In this section, we look at three types of t tests that are used for slightly different research designs: the one-sample t test, the dependent-samples t test, and the independent-samples t test.
14.2.3. One-Sample t Test¶
The one-sample t test is used to compare a sample mean (M) with a hypothetical population mean (\(\mu_0\)) that provides some interesting standard of comparison. The null hypothesis is that the mean for the population (\(\mu\)) is equal to the hypothetical population mean: \(\mu\) = \(\mu_0\). The alternative hypothesis is that the mean for the population is different from the hypothetical population mean: \(\mu \neq \mu_0\). To decide between these two hypotheses, we need to find the probability of obtaining the sample mean (or one more extreme) if the null hypothesis were true. But finding this p value requires first computing a test statistic called t. A test statistic is a statistic that is computed only to help find the p value. The formula for t is as follows:
Again, M is the sample mean and \(\mu_0\) is the hypothetical population mean of interest. SD is the sample standard deviation and N is the sample size.
The reason the t statistic (or any test statistic) is useful is that we know how it is distributed when the null hypothesis is true. As shown in Figure 14.2:, this distribution is unimodal and symmetrical, and it has a mean of 0. Its precise shape depends on a statistical concept called the degrees of freedom, which for a one-sample t test is N - 1 (there are 24 degrees of freedom for the distribution shown in Figure 14.2:). The important point is that knowing this distribution makes it possible to find the p value for any t score. Consider, for example, a t score of +1.50 based on a sample of 25. The probability of a t score at least this extreme is given by the proportion of t scores in the distribution that are at least this extreme. For now, let us define extreme as being far from zero in either direction. Thus the p value is the proportion of t scores that are +1.50 or above or that are -1.50 or below, a value that turns out to be .14.
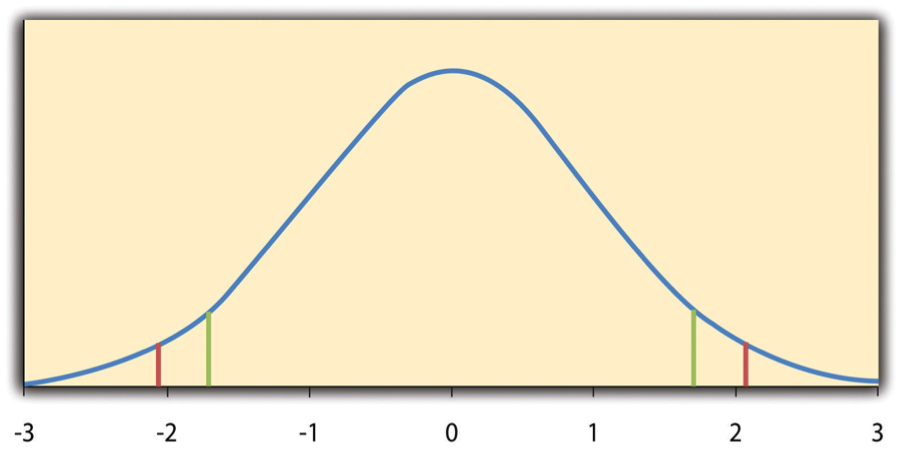
Fig. 14.2 Distribution of t Scores (with 24 Degrees of Freedom) when the null hypothesis is true. The red vertical lines represent the two-tailed critical values, and the green vertical lines the one-tailed critical values when \(\alpha\) = .05.¶
Fortunately, we do not have to deal directly with the distribution of t scores. If we were to enter our sample data and hypothetical mean of interest into one of the online statistical tools in Chapter 13 or into a program like SPSS, the output would include both the t score and the p value. At this point, the rest of the procedure is simple. If p is less than .05, we reject the null hypothesis and conclude that the population mean differs from the hypothetical mean of interest. If p is greater than .05, we conclude that there is not enough evidence to say that the population mean differs from the hypothetical mean of interest.
If we were to compute the t score by hand, we could use a table below to make the decision. This table does not provide actual p values. Instead, it provides the critical values of t for different degrees of freedom (df) when \(\alpha\) is .05. For now, let us focus on the two-tailed critical values in the last column of the table. Each of these values should be interpreted as a pair of values: one positive and one negative. For example, the two-tailed critical values when there are 24 degrees of freedom are +2.064 and -2.064. These are represented by the red vertical lines in Figure 14.2:. The idea is that any t score below the lower critical value (the left-hand red line in Figure Figure 14.2:) is in the lowest 2.5% of the distribution, while any t score above the upper critical value (the right-hand red line) is in the highest 2.5% of the distribution. Therefore any t score beyond the critical value in either direction is in the most extreme 5% of t scores when the null hypothesis is true and has a p value less than .05. Thus if the t score we compute is beyond the critical value in either direction, then we reject the null hypothesis. If the t score we compute is between the upper and lower critical values, then we retain the null hypothesis.
df |
Critical value (one-tailed) |
Critical value (Two-tailed) |
|---|---|---|
3 |
2.353 |
3.182 |
4 |
2.132 |
2.776 |
5 |
2.015 |
2.571 |
6 |
1.943 |
2.447 |
7 |
1.895 |
2.365 |
8 |
1.860 |
2.306 |
9 |
1.833 |
2.262 |
10 |
1.812 |
2.228 |
11 |
1.796 |
2.201 |
12 |
1.782 |
2.179 |
13 |
1.771 |
2.160 |
14 |
1.761 |
2.145 |
15 |
1.753 |
2.131 |
16 |
1.746 |
2.120 |
17 |
1.740 |
2.110 |
18 |
1.734 |
2.101 |
19 |
1.729 |
2.093 |
20 |
1.725 |
2.086 |
21 |
1.721 |
2.080 |
22 |
1.717 |
2.074 |
23 |
1.714 |
2.069 |
24 |
1.711 |
2.064 |
25 |
1.708 |
2.060 |
30 |
1.697 |
2.042 |
35 |
1.690 |
2.030 |
40 |
1.684 |
2.021 |
45 |
1.679 |
2.014 |
50 |
1.676 |
2.009 |
60 |
1.671 |
2.000 |
70 |
1.667 |
1.994 |
80 |
1.664 |
1.990 |
90 |
1.662 |
1.987 |
100 |
1.660 |
1.984 |
Thus far, we have considered what is called a two-tailed test, where we reject the null hypothesis if the t score for the sample is extreme in either direction. This test makes sense when we believe that the sample mean might differ from the hypothetical population mean but we do not have good reason to expect the difference to go in a particular direction. But it is also possible to do a one-tailed test, where we reject the null hypothesis only if the t score for the sample is extreme in one direction that we specify before collecting the data. This test makes sense when we have good reason to expect the sample mean will differ from the hypothetical population mean in a particular direction.
Here is how it works. Each one-tailed critical value in the table above can again be interpreted as a pair of values: one positive and one negative. A t score below the lower critical value is in the lowest 5% of the distribution, and a t score above the upper critical value is in the highest 5% of the distribution. For 24 degrees of freedom, these values are -1.711 and +1.711 (these are represented by the green vertical lines in Figure 14.2:). However, for a one-tailed test, we must decide before collecting data whether we expect the sample mean to be lower than the hypothetical population mean, in which case we would use only the lower critical value, or we expect the sample mean to be greater than the hypothetical population mean, in which case we would use only the upper critical value. Notice that we still reject the null hypothesis when the t score for our sample is in the most extreme 5% of the t scores we would expect if the null hypothesis were true, keeping \(\alpha\) at .05. We have simply redefined “extreme” to refer only to one tail of the distribution. The advantage of the one-tailed test is that critical values in that tail are less extreme. If the sample mean differs from the hypothetical population mean in the expected direction, then we have a better chance of rejecting the null hypothesis. The disadvantage is that if the sample mean differs from the hypothetical population mean in the unexpected direction, then there is no chance of rejecting the null hypothesis.
14.2.4. Example One-Sample t Test¶
Imagine that a health psychologist is interested in the accuracy of university students’ estimates of the number of calories in a chocolate chip cookie. He shows the cookie to a sample of 10 students and asks each one to estimate the number of calories in it. Because the actual number of calories in the cookie is 250, this is the hypothetical population mean of interest (\(\mu_0\)). The null hypothesis is that the mean estimate for the population (\(\mu\)) is 250. Because he has no real sense of whether the students will underestimate or overestimate the number of calories, he decides to do a two-tailed test. Now imagine further that the participants’ actual estimates are as follows:
250, 280, 200, 150, 175, 200, 200, 220, 180, 250
The mean estimate for the sample (M) is 212.00 calories and the standard deviation (SD) is 39.17. The health psychologist can now compute the t score for his sample:
If he enters the data into one of the online analysis tools or uses SPSS, it would also tell him that the two- tailed p value for this t score (with 10 - 1 = 9 degrees of freedom) is .013. Because this is less than .05, the health psychologist would reject the null hypothesis and conclude that university students tend to underestimate the number of calories in a chocolate chip cookie. If he computes the t score by hand, he could look at Table 13.2 and see that the critical value of t for a two-tailed test with 9 degrees of freedom is ±2.262. The fact that his t score was more extreme than this critical value would tell him that his p value is less than .05 and that he should reject the null hypothesis.
Finally, if this researcher had gone into this study with good reason to expect that university students underestimate the number of calories, then he could have done a one-tailed test instead of a two-tailed test. The only thing this decision would change is the critical value, which would be -1.833. This slightly less extreme value would make it a bit easier to reject the null hypothesis. However, if it turned out that university students overestimate the number of calories the researcher would not have been able to reject the null hypothesis, no matter how much they overestimated it.
14.2.5. The Dependent-Samples t Test¶
The dependent-samples t test (sometimes called the paired-samples t test) is used to compare two means (e.g., a group of participants measured at two different times or under two different conditions). This comparison is appropriate for pretest-posttest designs or within-subjects experiments. The null hypothesis is that the two means are the same in the population. The alternative hypothesis is that they are not the same. Like the one-sample t test, te dependent-samples t test can be one-tailed if the researcher has good reason to expect the difference goes in a particular direction.
It helps to think of the dependent-samples t test as a special case of the one-sample t test. However, the first step in the dependent-samples t test is to reduce the two scores for each participant to a single measurement by taking the difference between them. At this point, the dependent-samples t test becomes a one-sample t test on the difference scores. The hypothetical population mean (\(\mu_0\)) of interest is 0 because this is what the mean difference score would be if there were no difference between the two means. We can now think of the null hypothesis as being that the mean difference score in the population is 0 (\(\mu_0\) = 0) and the alternative hypothesis as being that the mean difference score in the population is not 0 (\(\mu_0 \neq 0\)).
14.2.6. Example Dependent-Samples t Test¶
Imagine that the health psychologist now knows that people tend to underestimate the number of calories in junk food and has developed a short training program to improve their estimates. To test the effectiveness of this program, he conducts a pretest-posttest study in which 10 participants estimate the number of calories in a chocolate chip cookie before the training program and then estimate the calories again afterward. Because he expects the program to increase participants’ estimates, he decides to conduct a one-tailed test. Now imagine further that the pretest estimates are:
230, 250, 280, 175, 150, 200, 180, 210, 220, 190
and that the posttest estimates (for the same participants in the same order) are:
250, 260, 250, 200, 160, 200, 200, 180, 230, 240.
The difference scores, then, are as follows:
+20, +10, -30, +25, +10, 0, +20, -30, +10, +50.
Note that it does not matter whether the first set of scores is subtracted from the second or the second from the first as long as it is done the same way for all participants. In this example, it makes sense to subtract the pretest estimates from the posttest estimates so that positive difference scores mean that the estimates went up after the training and negative difference scores mean the estimates went down.
The mean of the difference scores is 8.50 with a standard deviation of 27.27. The health psychologist can now compute the t score for his sample as follows:
If he enters the data into one of the online analysis tools or uses Excel or SPSS, it would tell him that the one-tailed p value for this t score (again with 10 - 1 = 9 degrees of freedom) is .148. Because this is greater than .05, he would fail to reject the null hypothesis; he does not have enough evidence to suggest that the training program increases calorie estimates. If he were to compute the t score by hand, he could look at the table above and see that the critical value of t for a one-tailed test with 9 degrees of freedom is +1.833 (positive because he was expecting a positive mean difference score). The fact that his t score was less extreme than this critical value would tell him that his p value is greater than .05 and that the results fail to reject the null hypothesis.
14.2.7. The Independent-Samples t Test¶
The independent-samples t test is used to compare the means of two separate samples (M1 and M2). The two samples might have been tested under different conditions in a between-subjects experiment, or they could be preexisting groups in a correlational design (e.g., women and men or extraverts and introverts). The null hypothesis is that the two means: \(\mu_1 = \)\mu_2\(. The alternative hypothesis is that they are not the same: \)\mu_1 \neq \mu_2$. Again, the test can be one-tailed if the researcher has good reason to expect the difference goes in a particular direction.
The t statistic here is a bit more complicated because it must take into account two sample means, two standard deviations, and two sample sizes. The formula is as follows:
Notice that this formula includes squared standard deviations (the variances) that appear inside the square root symbol. Also, lowercase n1 and n2 refer to the sample sizes in the two groups or condition (as opposed to capital N, which generally refers to the total sample size). The only additional thing to know here is that there are N - 2 degrees of freedom for the independent-samples t test.
14.2.8. Example Independent-Samples t test¶
Now the health psychologist wants to compare the calorie estimates of people who regularly eat junk food with the estimates of people who rarely eat junk food. He believes the difference could come out in either direction so he decides to conduct a two-tailed test. He collects data from a sample of eight participants who eat junk food regularly and seven participants who rarely eat junk food. The data are as follows:
Junk food eaters: 180, 220, 150, 85, 200, 170, 150, 190
Non–junk food eaters: 200, 240, 190, 175, 200, 300, 240
The mean for the junk food eaters is 220.71 with a standard deviation of 41.23. The mean for the non–junk food eaters is 168.12 with a standard deviation of 42.66. He can now compute his t score as follows:
If he enters the data into one of the online analysis tools or uses Excel or SPSS, it would tell him that the two-tailed p value for this t score (with 15 - 2 = 13 degrees of freedom) is .015. Because this p value is less than .05, the health psychologist would reject the null hypothesis and conclude that people who eat junk food regularly make lower calorie estimates than people who eat it rarely. If he were to compute the t score by hand, he could look at the table above and see that the critical value of t for a two-tailed test with 13 degrees of freedom is 2.160 (and/or -2.160). The fact that the observed t score was more extreme than this critical value would tell him that his p value is less than .05 and that he should reject the null hypothesis.
14.2.9. The Analysis of Variance¶
When there are more than two groups or condition means to be compared, the most common null hypothesis test is the analysis of variance (ANOVA). In this section, we look primarily at the one-way ANOVA, which is used for between-subjects designs with a single independent variable. We then briefly consider some other versions of the ANOVA that are used for within-subjects and factorial research designs.
14.2.10. One-Way ANOVA¶
The one-way ANOVA is used to compare the means of more than two samples (\(M_1, M_2, \ldots M_G\)) in a between-subjects design. The null hypothesis is that all the means are equal in the population: \(\mu_1=\mu_2= \ldots = \mu_G\). The alternative hypothesis is that not all the means in the population are equal.
The test statistic for the ANOVA is called F. It is a ratio of two estimates of the population variance based on the sample data. One estimate of the population variance is called the mean squares between groups (MSB) and is based on the differences among the sample means. The other is called the mean squares within groups (MSW) and is based on the differences among the scores within each group. The F statistic is the ratio of the \(MS_B\) to the \(MS_W\) and can therefore be expressed as follows:
Again, the reason that F is useful is that we know how it is distributed when the null hypothesis is true. As shown in Figure 14.3:, this distribution is unimodal and positively skewed with values that cluster around 1. The precise shape of the distribution depends on both the number of groups and the sample size, and there is a degrees of freedom value associated with each of these. The between-groups degrees of freedom is the number of groups minus one: \(df_B = (G - 1)\). The within-groups degrees of freedom is the total sample size minus the number of groups: \(df_W = N - G\). Again, knowing the distribution of F when the null hypothesis is true allows us to find the p value.
As with the t test, there are online tools and statistical software such as Excel and SPSS that will compute F and find the p value for you. If p is less than .05, then we reject the null hypothesis and conclude that there are differences among the group means in the population.
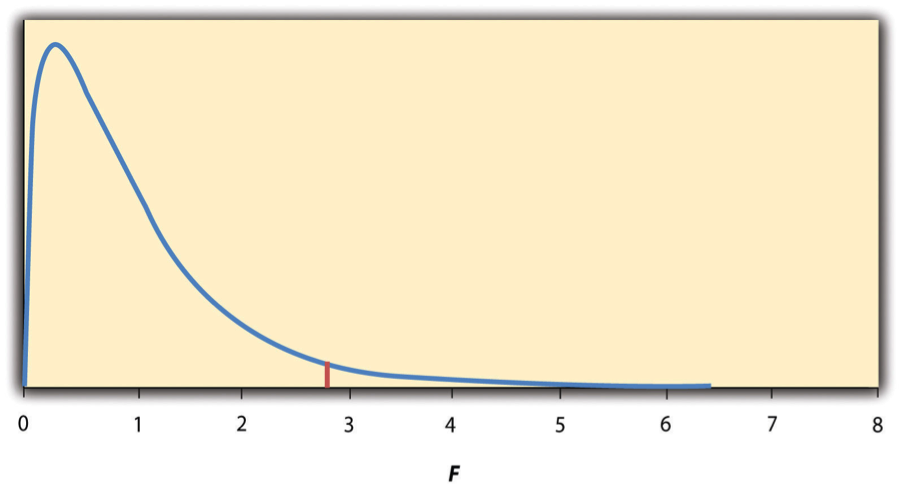
Fig. 14.3 Distribution of the F Ratio With 2 and 37 Degrees of Freedom When the Null Hypothesis Is True. The red vertical line represents the critical value when \(\alpha\) is .05.¶
If p is greater than .05, then we cannot reject the null hypothesis and conclude that there is not enough evidence to say that there are differences. In the unlikely event that we would compute F by hand, we can use a table of critical values like those in the table below to make the decision. The idea is that any F ratio greater than the critical value has a p value of less than .05. Thus if the F ratio we compute is beyond the critical value, then we reject the null hypothesis. If the F ratio we compute is less than the critical value, then we retain the null hypothesis.
\(df_W\) |
\(df_B=2\) |
\(df_B=3\) |
\(df_B=4\) |
|---|---|---|---|
8 |
4.459 |
4.066 |
3.838 |
9 |
4.256 |
3.863 |
3.633 |
10 |
4.103 |
3.708 |
3.478 |
11 |
3.982 |
3.587 |
3.357 |
12 |
3.885 |
3.490 |
3.259 |
13 |
3.806 |
3.411 |
3.179 |
14 |
3.739 |
3.344 |
3.112 |
15 |
3.682 |
3.287 |
3.056 |
16 |
3.634 |
3.239 |
3.007 |
17 |
3.592 |
3.197 |
2.965 |
18 |
3.555 |
3.160 |
2.928 |
19 |
3.522 |
3.127 |
2.895 |
20 |
3.493 |
3.098 |
2.866 |
21 |
3.467 |
3.072 |
2.840 |
22 |
3.443 |
3.049 |
2.817 |
23 |
3.422 |
3.028 |
2.796 |
24 |
3.403 |
3.009 |
2.776 |
25 |
3.385 |
2.991 |
2.759 |
30 |
3.316 |
2.922 |
2.690 |
35 |
3.267 |
2.874 |
2.641 |
40 |
3.232 |
2.839 |
2.606 |
45 |
3.204 |
2.812 |
2.579 |
50 |
3.183 |
2.790 |
2.557 |
55 |
3.165 |
2.773 |
2.540 |
60 |
3.150 |
2.758 |
2.525 |
65 |
3.138 |
2.746 |
2.513 |
70 |
3.128 |
2.736 |
2.503 |
75 |
3.119 |
2.727 |
2.494 |
80 |
3.111 |
2.719 |
2.486 |
85 |
3.104 |
2.712 |
2.479 |
90 |
3.098 |
2.706 |
2.473 |
95 |
3.092 |
2.700 |
2.467 |
100 |
3.087 |
2.696 |
2.463 |
14.2.11. Example One-Way ANOVA¶
Imagine that the health psychologist wants to compare the calorie estimates of psychology majors, nutrition majors, and professional dieticians. He collects the following data:
Psych majors: 200, 180, 220, 160, 150, 200, 190, 200
Nutrition majors: 190, 220, 200, 230, 160, 150, 200, 210, 195
Dieticians: 220, 250, 240, 275, 250, 230, 200, 240
The means are 187.50 (SD = 23.14), 195.00 (SD = 27.77), and 238.13 (SD = 22.35), respectively. So it appears that dieticians made substantially more accurate estimates on average. The researcher would almost certainly enter these data into a program such as Excel or SPSS, which would compute F for him and find the p value. The table below shows the output you might see when performing a one-way ANOVA on these results. This table is referred to as an ANOVA table. It shows that \(MS_B\) is 5,971.88, \(MS_W\) is 602.23, and their ratio, F, is 9.92. The p value is .0009. Because this value is below .05, the researcher would reject the null hypothesis and conclude that the mean calorie estimates for the three groups are not the same in the population. Notice that the ANOVA table also includes the “sum of squares” (SS) for between groups and for within groups. These values are computed on the way to finding \(MS_B\) and \(MS_W\) but are not typically reported by the researcher. Finally, if the researcher were to compute the F ratio by hand, he could look at the table above and see that the critical value of F with 2 and 21 degrees of freedom is 3.467. The fact that his F score was more extreme than this critical value would tell him that his p value is less than .05 and that he should reject the null hypothesis.
Source of variation |
SS |
df |
MS |
F |
p-value |
\(F_{crit}\) |
|---|---|---|---|---|---|---|
Between groups |
11,943.75 |
2 |
5,971.875 |
9.916234 |
0.000928 |
3.4668 |
Within groups |
12,646.88 |
21 |
602.2321 |
|||
Total |
24,590.63 |
23 |
14.2.12. ANOVA Elaborations¶
14.2.12.1. Post Hoc Comparisons¶
When we reject the null hypothesis in a one-way ANOVA, we conclude that the group means are not all the same in the population. But this can indicate different things. With three groups, it can indicate that all three means are significantly different from each other. Or it can indicate that one of the means is significantly different from the other two, but the other two are not significantly different from each other. It could be, for example, that the mean calorie estimates of psychology majors, nutrition majors, and dieticians are all significantly different from each other. Or it could be that the mean for dieticians is significantly different from the means for psychology and nutrition majors, but the means for psychology and nutrition majors are not significantly different from each other. For this reason, statistically significant one-way ANOVA results are typically followed up with a series of post hoc comparisons of selected pairs of group means to determine which are different from which others.
One approach to post hoc comparisons would be to conduct a series of independent-samples t tests comparing each group mean to each of the other group means. But there is a problem with this approach. In general, if we conduct a t test when the null hypothesis is true, we have a 5% chance of mistakenly rejecting the null hypothesis. If we conduct several t tests when the null hypothesis is true, the chance of mistakenly rejecting at least one null hypothesis increases with each test we conduct. Thus, researchers do not usually make post hoc comparisons using standard t tests because there is too great a chance that they will mistakenly reject at least one null hypothesis. Instead, they use one of several modified t test procedures, including the Bonferonni procedure, Fisher’s least significant difference (LSD) test, and Tukey’s honestly significant difference (HSD) test. The details of these approaches are beyond the scope of this book, but it is important to understand their purpose. It is to keep the risk of mistakenly rejecting a true null hypothesis to an acceptable level (close to 5%).
14.2.12.2. Repeated-Measures ANOVA¶
Recall that the one-way ANOVA is appropriate for between-subjects designs in which the means being compared come from separate groups of participants. It is not appropriate for within-subjects designs in which the means being compared come from the same participants tested under different conditions or at different times. This requires a slightly different approach, called the repeated-measures ANOVA. The basics of the repeated-measures ANOVA are the same as for the one-way ANOVA. The main difference is that measuring the dependent variable multiple times for each participant allows for a more refined measure of \(MS_W\). Imagine, for example, that the dependent variable in a study is a measure of reaction time. Some participants will be faster or slower than others overall. This may be because of stable individual differences in their nervous systems, muscles, and other factors. In a between-subjects design, these stable individual differences would simply add to the variability within the groups and increase the value of \(MS_W\). In a within-subjects design, however, these stable individual differences can be measured and subtracted from the value of \(MS_W\). This lower value of \(MS_W\) means a higher value of F and a more sensitive test.
14.2.12.3. Factorial ANOVA¶
When more than one independent variable is included in a factorial design, the appropriate approach is the factorial ANOVA. Again, the basics of the factorial ANOVA are the same as for the one-way and repeated- measures ANOVAs. The main difference is that it produces an F ratio and p value for each main effect and for each interaction. Returning to our calorie estimation example, imagine that the health psychologist tests the effect of participant major (psychology vs. nutrition) and food type (cookie vs. hamburger) in a factorial design. A factorial ANOVA would produce separate F ratios and p values for the main effect of major, the main effect of food type, and the interaction between major and food. Appropriate modifications must be made depending on whether the design is between subjects, within subjects, or mixed.
14.2.13. Testing Pearson’s r¶
For relationships between quantitative variables, where Pearson’s r is used to describe the strength of those relationships, the appropriate null hypothesis test is a test of Pearson’s r. The basic logic is exactly the same as for other null hypothesis tests. In this case, the null hypothesis is that there is no relationship in the population. We can use the Greek lowercase rho (\(\rho\)) to represent the relevant parameter: \(\rho = 0\). The alternative hypothesis is that there is a relationship in the population: \(\rho \neq 0\). As with the t test, this test can be two-tailed if the researcher has no expectation about the direction of the relationship or one-tailed if the researcher expects the relationship to go in a particular direction.
It is possible to use Pearson’s r for the sample to compute a t score with N - 2 degrees of freedom and then to proceed as for a t test. However, because of the way it is computed, Pearson’s r can also be treated as its own test statistic. The online statistical tools and statistical software such as Excel and SPSS generally compute Pearson’s r and provide the p value associated with that value of Pearson’s r. As always, if the p value is less than .05, we reject the null hypothesis and conclude that there is a relationship between the variables in the population. If the p value is greater than .05, we retain the null hypothesis and conclude that there is not enough evidence to say there is a relationship in the population. If we compute Pearson’s r by hand, we can use a table like the one below, which shows the critical values of r for various samples sizes when \(\alpha\) is .05. A sample value of Pearson’s r that is more extreme than the critical value is statistically significant.
N |
One-tailed |
Two-tailed |
|---|---|---|
5 |
.805 |
.878 |
10 |
.549 |
.632 |
15 |
.441 |
.514 |
20 |
.378 |
.444 |
25 |
.337 |
.396 |
30 |
.306 |
.361 |
35 |
.283 |
.334 |
40 |
.264 |
.312 |
45 |
.248 |
.294 |
50 |
.235 |
.279 |
55 |
.224 |
.266 |
60 |
.214 |
.254 |
65 |
.206 |
.244 |
70 |
.198 |
.235 |
75 |
.191 |
.227 |
80 |
.185 |
.220 |
85 |
.180 |
.213 |
90 |
.174 |
.207 |
95 |
.170 |
.202 |
100 |
.165 |
.197 |
14.2.14. Example Test of Pearson’s r¶
Imagine that the health psychologist is interested in the correlation between people’s calorie estimates and their weight. He has no expectation about the direction of the relationship, so he decides to conduct a two-tailed test. He computes the correlation for a sample of 22 university students and finds that Pearson’s r is -0.21. The statistical software he uses tells him that the p value is 0.348. It is greater than .05, so he cannot reject the null hypothesis and concludes that there is not enough evidence to suggest a relationship between people’s calorie estimates and their weight. If he were to compute Pearson’s r by hand, he could look at the table above and see that the critical value for 22 - 2 = 20 degrees of freedom is .444. The fact that Pearson’s r for the sample is less extreme than this critical value tells him that the p value is greater than .05 and that he should retain the null hypothesis.
14.2.15. Key Takeaways¶
To compare two means, the most common null hypothesis test is the t test. The one-sample t test is used for comparing one sample mean with a hypothetical population mean of interest, the dependent-samples t test is used to compare two means in a within-subjects design, and the independent-samples t test is used to compare two means in a between-subjects design.
To compare more than two means, the most common null hypothesis test is the analysis of variance (ANOVA). The one-way ANOVA is used for between-subjects designs with one independent variable, the repeated-measures ANOVA is used for within-subjects designs, and the factorial ANOVA is used for factorial designs.
A null hypothesis test of Pearson’s r is used to compare a sample value of Pearson’s r with a hypothetical population value of 0.
14.2.16. Exercises¶
Practice: Use one of the online tools, Excel, or SPSS to reproduce the one-sample t test, dependent-samples t test, independent-samples t test, and one-way ANOVA for the four sets of calorie estimation data presented in this section.
Practice: A sample of 25 university students rated their friendliness on a scale of 1 (Much Lower Than Average) to 7 (Much Higher Than Average). Their mean rating was 5.30 with a standard deviation of 1.50. Conduct a one-sample t test comparing their mean rating with a hypothetical mean rating of 4 (Average). The question is whether university students have a tendency to rate themselves as friendlier than average.
Practice: Decide whether each of the following Pearson’s r values is statistically significant for both a one-tailed and a two-tailed test.
a. The correlation between height and IQ is +.13 in a sample of 35.
b. For a sample of 88 university students, the correlation between how disgusted they felt and the harshness of their moral judgments was +.23.
c. The correlation between the number of daily hassles and positive mood is -.43 for a sample of 30 middle-aged adults.
14.3. Additional Considerations¶
14.3.1. Learning Objectives¶
Define Type I and Type II errors, explain why they occur, and identify some steps that can be taken to minimize their likelihood.
Define statistical power, explain its role in the planning of new studies, and use online tools to compute the statistical power of simple research designs.
List some criticisms of conventional null hypothesis testing, along with some ways of dealing with these criticisms.
In this section, we consider a few other issues related to null hypothesis testing, including some that are useful in planning studies and interpreting results. We even consider some long-standing criticisms of null hypothesis testing, along with some steps that researchers in psychology have taken to address them.
14.3.2. Errors in Null Hypothesis Testing¶
In null hypothesis testing, the researcher tries to draw a reasonable conclusion about the population based on the sample. Unfortunately, this conclusion is not guaranteed to be correct. This discrepancy is illustrated by Figure 14.4:. The rows of this table represent the two possible decisions that we can make: to reject or retain the null hypothesis. The columns represent the two possible states of the world: the null hypothesis is false or it is true. The four cells of the table, then, represent the four distinct outcomes of a null hypothesis test. Two of the outcomes are correct: rejecting the null hypothesis when it is false and retaining it when it is true. The other two are errors: rejecting the null hypothesis when it is true and retaining it when it is false.
Rejecting the null hypothesis when it is true is called a Type I error. This error means that we have concluded that there is a relationship in the population when in fact there is not. Type I errors occur because even when there is no relationship in the population, sampling error alone will occasionally produce an extreme result. In fact, when the null hypothesis is true and \(\alpha\) is .05, we will mistakenly reject the null hypothesis 5% of the time (thus \(\alpha\) is sometimes referred to as the “Type I error rate”). Retaining the null hypothesis when it is false is called a Type II error. This error means that we have concluded that there is no relationship in the population when in fact there is. In practice, Type II errors occur primarily because the research design lacks adequate statistical power to detect the relationship (e.g., the sample is too small). We will have more to say about statistical power shortly.
In principle, it is possible to reduce the chance of a Type I error by setting \(\alpha\) to something less than .05. Setting it to .01, for example, would mean that if the null hypothesis is true, then there is only a 1% chance of mistakenly rejecting it. But making it harder to reject true null hypotheses also makes it harder to reject false ones and therefore increases the chance of a Type II error. Similarly, it is possible to reduce the chance of a Type II error by setting \(\alpha\) to something greater than .05 (e.g., .10). But making it easier to reject false null hypotheses also makes it easier to reject true ones and therefore increases the chance of a Type I error. This provides some insight into why the convention is to set \(\alpha\) to .05. The conventional level of \(\alpha=.05\) represents a particular balance between the rates of both Type I and Type II errors.
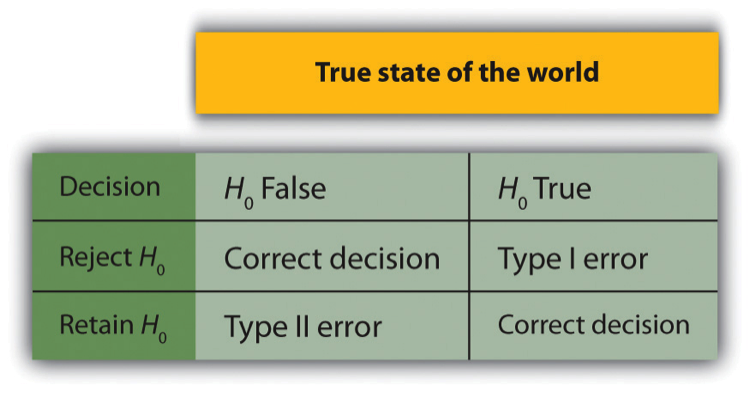
Fig. 14.4 Two Types of Correct Decisions and Two Types of Errors in Null Hypothesis Testing¶
The possibility of committing Type I and Type II errors has several important implications for interpreting the results of our own and others’ research. One is that we should be cautious about interpreting the results of any individual study because there is a chance that it’s results reflect a Type I or Type II error. This possibility is why researchers consider it important to replicate their studies. Each time researchers replicate a study and find a similar result, they rightly become more confident that the result represents a real phenomenon and not just a Type I or Type II error.
Another issue related to Type I errors is the so-called file drawer problem [Ros79]. The idea is that when researchers obtain statistically significant results, they tend to submit them for publication, and journal editors and reviewers tend to accept them. But when researchers obtain non-significant results, they tend not to submit them for publication, or if they do submit them, journal editors and reviewers tend not to accept them. Researchers end up putting these non-significant results away in a file drawer (or nowadays, in a folder on their hard drive). One effect of this tendency is that the published literature probably contains a higher proportion of Type I errors than we might expect on the basis of statistical considerations alone. Even when there is a relationship between two variables in the population, the published research literature is likely to overstate the strength of that relationship. Imagine, for example, that the relationship between two variables in the population is positive but weak (e.g., \(\rho\) = +0.10). If several researchers conduct studies on this relationship, sampling error is likely to produce results ranging from weak negative relationships (e.g., r = -0.10) to moderately strong positive ones (e.g., r = +0.40). But because of the file drawer problem, it is likely that only those studies producing moderate to strong positive relationships are published. The result is that the effect reported in the published literature tends to be stronger than it really is in the population.
The file drawer problem is a difficult one because it is a product of the way scientific research has traditionally been conducted and published. One solution might be for journal editors and reviewers to evaluate research submitted for publication without knowing the results of that research. The idea is that if the research question is judged to be interesting and the method judged to be sound, then a non-significant result should be just as important and worthy of publication as a significant one. Short of such a radical change in how research is evaluated for publication, researchers can still take pains to keep their non-significant results and share them as widely as possible (e.g., at professional conferences). Many scientific disciplines now have mechanisms for publishing non-significant results. In psychology, for example, there is an increasing use of registered reprorts, which are studies that are designed and reviewed before ever being conducted. Because publishing decisions are made before data is collected and before making statistical decisions, the literature is less likely to be biased by the file drawer problem.
In 2014, Uri Simonsohn, Leif Nelson, and Joseph Simmons published a leveling article at the field of psychology accusing researchers of creating too many Type I errors in psychology by chasing a significant p value through what they called p-hacking [SNS14]. Researchers are trained in many sophisticated statistical techniques for analyzing data that will yield a desirable p value. They propose using a p-curve to determine whether the data set with a certain p value is credible or not. They also propose this p-curve as a way to unlock the file drawer because we can only understand the finding if we know the true effect size and the likelihood of a result was found after multiple attempts at not finding a result. Their groundbreaking paper contributed to a major conversation in the field about publishing standards and the reliability of our results.
14.3.3. Statistical Power¶
The statistical power of a research design is the probability of rejecting the null hypothesis given the sample size and expected relationship strength. For example, the statistical power of a study with 50 participants and an expected Pearson’s r of 0.30 in the population is 0.59. That is, there is a 59% chance of rejecting the null hypothesis if indeed the population correlation is 0.30. Statistical power is the complement of the probability of committing a Type II error. So in this example, the probability of committing a Type II error would be 1 - .59 = .41. Clearly, researchers should be interested in the power of their research designs if they want to avoid making Type II errors. In particular, they should make sure their research design has adequate power before collecting data. A common guideline is that a power of .80 is adequate. This guideline means that there is an 80% chance of rejecting the null hypothesis for the expected relationship strength.
The topic of how to compute power for various research designs and null hypothesis tests is beyond the scope of this book. However, there are online tools that allow you to do this by entering your sample size, expected relationship strength, and \(\alpha\) level for various hypothesis tests (see below). In addition, Figure 14.5 shows the sample size needed to achieve a power of .80 for weak, medium, and strong relationships for a two- tailed independent-samples t test and for a two-tailed test of Pearson’s r. Notice that this table amplifies the point made earlier about relationship strength, sample size, and statistical significance. In particular, weak relationships require very large samples to provide adequate statistical power.
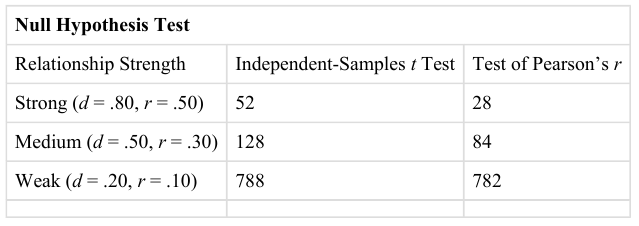
Fig. 14.5 Sample sizes needed to achieve statistical power of .80 for different expected relationship strengths for an independent-samples t test and a test of pearson’s r null hypothesis test¶
What should you do if you discover that your research design does not have adequate power? Imagine, for example, that you are conducting a between-subjects experiment with 20 participants in each of two conditions and that you expect a medium difference (d = .50) in the population. The statistical power of this design is only .34. That is, even if there is a medium difference in the population, there is only about a one in three chance of rejecting the null hypothesis and about a two in three chance of committing a Type II error.
Given the time and effort involved in conducting the study, this probably seems like an unacceptably low chance of rejecting the null hypothesis and an unacceptably high chance of committing a Type II error. Given that statistical power depends primarily on relationship strength and sample size, there are essentially two steps you can take to increase statistical power: increase the strength of the relationship or increase the sample size. Increasing the strength of the relationship can sometimes be accomplished by using a stronger manipulation or by more carefully controlling extraneous variables to reduce the amount of noise in the data (e.g., by using a within-subjects design rather than a between-subjects design). The usual strategy, however, is to increase the sample size. For any expected relationship strength, there will always be some sample large enough to achieve adequate power.
14.3.4. Computing Power Online¶
The following links are to tools that allow you to compute statistical power for various research designs and null hypothesis tests by entering information about the expected relationship strength, the sample size, and the \(\alpha\) level. They also allow you to compute the sample size necessary to achieve your desired level of power (e.g., .80). The first is an online tool. The second is a free downloadable program called G*Power.
14.3.5. Problems With Null Hypothesis Testing, and Some Solutions¶
Again, null hypothesis testing is the most common approach to inferential statistics in psychology. It is not without its critics, however. In fact, in recent years the criticisms have become so prominent that the American Psychological Association convened a task force to make recommendations about how to deal with them [Wil99]. In this section, we consider some of the criticisms and some of the recommendations.
14.3.6. Criticisms of Null Hypothesis Testing¶
Some criticisms of null hypothesis testing focus on researchers’ misunderstanding of it. We have already seen, for example, that the p value is widely misinterpreted as the probability that the null hypothesis is true (recall that it is really the probability of the sample result if the null hypothesis were true). A closely related misinterpretation is that 1 - p is the probability of replicating a statistically significant result. In one study, 60% of a sample of professional researchers thought that a p value of .01 (for an independent-samples t test with 20 participants in each sample) meant there was a 99% chance of replicating the statistically significant result [Oak86]. Our earlier discussion of power should make it clear that this figure is far too optimistic. As the table of critical values of Pearson’s r presented above, even if there were a large difference between means in the population, it would require 26 participants per sample to achieve a power of .80. And the program G*Power shows that it would require 59 participants per sample to achieve a power of .99.
Another set of criticisms focuses on the logic of null hypothesis testing. To many, the strict convention of rejecting the null hypothesis when p is less than .05 and retaining it when p is greater than .05 makes little sense. This criticism does not have to do with the specific value of .05 but with the idea that there should be any rigid dividing line between results that are considered significant and results that are not. Imagine two studies on the same statistical relationship with similar sample sizes. One has a p value of .04 and the other a p value of .06. Although the two studies have produced essentially the same result, the former is likely to be considered interesting and worthy of publication and the latter simply not significant. This convention is likely to prevent good research from being published and to contribute to the file drawer problem.
Yet another set of criticisms focus on the idea that null hypothesis testing, even when understood and carried out correctly, is simply not very informative. Recall that the null hypothesis is that there is no relationship between variables in the population (e.g., Cohen’s d or Pearson’s r is precisely 0). So to reject the null hypothesis is simply to say that there is some nonzero relationship in the population. But this assertion is not really saying very much. Imagine if chemistry could tell us only that there is some relationship between the temperature of a gas and its volume, rather than providing a precise equation to describe that relationship. Some critics even argue that the relationship between two variables in the population is never precisely 0 if it is carried out to enough decimal places. In other words, the null hypothesis is never literally true. So rejecting it does not tell us anything we did not already know!
To be fair, many researchers have come to the defense of null hypothesis testing. One of them, Robert Abelson, has argued that when it is correctly understood and carried out, null hypothesis testing does serve an important purpose [Abe12]. Especially when dealing with new phenomena, it gives researchers a principled way to convince others that their results should not be dismissed as mere chance occurrences.
14.3.7. The end of p-values?¶
In 2015, the editors of Basic and Applied Social Psychology announced6 a ban on the use of null hypothesis testing and related statistical procedures. Authors are welcome to submit papers with p-values, but the editors will remove them before publication. Although they did not propose a better statistical test to replace null hypothesis testing, the editors emphasized the importance of descriptive statistics and effect sizes. This rejection of the “gold standard” of statistical validity has continued the conversation in psychology of questioning exactly what we know.
14.3.8. What to Do?¶
Even those who defend null hypothesis testing recognize many of the problems with it. But what should be done? Some suggestions now appear in the Publication Manual. One is that each null hypothesis test should be accompanied by an effect size measure such as Cohen’s d or Pearson’s r. By doing so, the researcher provides an estimate of how strong the relationship in the population is—not just whether there is one or not. Remember that the p value cannot be interpreted as a direct measure of relationship strength because it also depends on the sample size. Even a very weak result can be statistically significant if the sample is large enough.
Another suggestion is to use confidence intervals rather than null hypothesis tests. A confidence interval around a statistic is a range of values that are likely to include the population parameter. For example, a sample of 20 university students might have a mean calorie estimate for a chocolate chip cookie of 200 with a 95% confidence interval of 160 to 240. Advocates of confidence intervals argue that they are much easier to interpret than null hypothesis tests. Another advantage of confidence intervals is that they provide the information necessary to do null hypothesis tests should anyone want to. In this example, the sample mean of 200 is significantly different at the .05 level from any hypothetical population mean that lies outside the confidence interval. So the confidence interval of 160 to 240 tells us that the sample mean is statistically significantly different from a hypothetical population mean of 250.
Finally, there are more radical solutions to the problems of null hypothesis testing that involve using very different approaches to inferential statistics. Bayesian statistics, for example, is an approach in which the researcher specifies the probability that the null hypothesis and any important alternative hypotheses are true before conducting the study, conducts the study, and then updates the probabilities based on the data. It is too early to say whether this approach will become common in psychological research. For now, null hypothesis testing, complemented by effect size measures and confidence intervals, remains the dominant approach.
14.3.9. Key Takeaways¶
The decision to reject or retain the null hypothesis is not guaranteed to be correct. A Type I error occurs when one rejects the null hypothesis when it is true. A Type II error occurs when one fails to reject the null hypothesis when it is false.
The statistical power of a research design is the probability of rejecting the null hypothesis given the expected relationship strength in the population and the sample size. Researchers should make sure that their studies have adequate statistical power before conducting them.
Null hypothesis testing has been criticized on the grounds that researchers misunderstand it, that it is illogical, and that it is uninformative. Others argue that it serves an important purpose—especially when used with effect size measures, confidence intervals, and other techniques. It remains the dominant approach to inferential statistics in psychology.
14.3.10. Exercises¶
Discussion: A researcher compares the effectiveness of two forms of psychotherapy for social phobia using an independent-samples t test. a. Explain what it would mean for the researcher to commit a Type I error. b. Explain what it would mean for the researcher to commit a Type II error.
Discussion: Imagine that you conduct a t test and the p value is .02. How could you explain what this p value means to someone who is not already familiar with null hypothesis testing? Be sure to avoid the common misinterpretations of the p value.
For additional practice with Type I and Type II errors, try these problems from Carnegie Mellon’s Open Learning Initiative.
14.4. From the “Replication Crisis” to Open Science Practices¶
14.4.1. Learning Objectives¶
Describe what is meant by the “replication crisis” in psychology.
Describe some questionable research practices.
Identify some ways in which scientific rigor may be increased.
Understand the importance of openness in psychological science.
At the start of this book we discussed the “Many Labs Replication Project”, which failed to replicate the original finding by Simone Schnall and her colleagues that washing one’s hands leads people to view moral transgressions as less wrong [SBH08]. Although this project is a good illustration of the collaborative and self-correcting nature of science, it also represents one specific response to psychology’s recent replication crisis”, a phrase that refers to the inability of researchers to replicate earlier research findings. Consider for example the results of the Reproducibility Project, which involved over 270 psychologists around the world coordinating their efforts to test the reliability of 100 previously published psychological experiments [C+15]. Although 97 of the original 100 studies had found statistically significant effects, only 36 of the replications did! Moreover, even the effect sizes of the replications were, on average, half of those found in the original studies (see Figure 13.5). Of course, a failure to replicate a result by itself does not necessarily discredit the original study as differences in the statistical power, populations sampled, and procedures used, or even the effects of moderating variables could explain the different results.
Although many believe that the failure to replicate research results is an expected characteristic of cumulative scientific progress, others have interpreted this situation as evidence of systematic problems with conventional scholarship in psychology, including a publication bias that favors the discovery and publication of counter-intuitive but statistically significant findings instead of the duller (but incredibly vital) process of replicating previous findings to test their robustness [PH12].
Worse still is the suggestion that the low replicability of many studies is evidence of the widespread use of questionable research practices by psychological researchers. These may include:
The selective deletion of outliers in order to influence (usually by artificially inflating) statistical relationships among the measured variables.
The selective reporting of results, cherry-picking only those findings that support one’s hypotheses.
Mining the data without an a priori hypothesis, only to claim that a statistically significant result had been originally predicted, a practice referred to as “HARKing” or hypothesizing after the results are known [Ker98].
A practice colloquially known as “p-hacking” (briefly discussed in the previous section), in which a researcher might perform inferential statistical calculations to see if a result was significant before deciding whether to recruit additional participants and collect more data [HHL+15]. As you have learned, the probability of finding a statistically significant result is influenced by the number of participants in the study.
Outright fabrication of data (as in the case of Diederik Stapel, described at the start of Chapter 3), although this would be a case of fraud rather than a “research practice”.
It is important to shed light on these questionable research practices to ensure that current and future researchers (such as yourself) understand the damage they wreak to the integrity and reputation of our discipline (see, for example, the “Replication Index”, a statistical “doping test” developed by Ulrich Schimmack in 2014 for estimating the replicability of studies, journals, and even specific researchers). However, in addition to highlighting what not to do, this so-called “crisis” has also highlighted the importance of enhancing scientific rigor by:
Designing and conducting studies that have sufficient statistical power, in order to increase the reliability of findings.
Publishing both null and significant findings (thereby counteracting the publication bias and reducing the file drawer problem).
Describing one’s research designs in sufficient detail to enable other researchers to replicate your study using an identical or at least very similar procedure.
Conducting high-quality replications and publishing these results [BID+14].
One particularly promising response to the replicability crisis has been the emergence of open science practices that increase the transparency and openness of the scientific enterprise. For example, Psychological Science (the flagship journal of the Association for Psychological Science) and other journals now issue digital badges to researchers who pre-registered their hypotheses and data analysis plans, openly shared their research materials with other researchers (e.g., to enable attempts at replication), or made available their raw data with other researchers (see Figure 13.6).
These initiatives, which have been spearheaded by the Center for Open Science, have led to the development of Transparency and Openness Promotion guidelines that have since been formally adopted by more than 500 journals and 50 organizations, a list that grows each week. When you add to this the requirements recently imposed by federal funding agencies in Canada (the Tri-Council) and the United States (National Science Foundation) concerning the publication of publicly-funded research in open access journals, it certainly appears that the future of science and psychology will be one that embraces greater “openness” [NAB+15].
14.4.2. Key Takeaways¶
In recent years psychology has grappled with a failure to replicate research findings. Some have interpreted this as a normal aspect of science but others have suggested that this is highlights problems stemming from questionable research practices.
One response to this “replicability crisis” has been the emergence of open science practices, which increase the transparency and openness of the research process. These open practices include digital badges to encourage pre-registration of hypotheses and the sharing of raw data and research materials.
14.4.3. Exercises¶
Discussion: What do you think are some of the key benefits of the adoption of open science practices such as pre-registration and the sharing of raw data and research materials? Can you identify any drawbacks of these practices?
Practice: Read the online article “Science isn’t broken: It’s just a hell of a lot harder than we give it credit for” and use the interactive tool entitled “Hack your way to scientific glory” in order to better understand the data malpractice of “p-hacking.”